As GPU-accelerated systems become increasingly common in the HPC world, the challenge for domain scientists is to update their computational codes to take full advantage of these new architectures. This article provides a high-level introduction to the main considerations for GPU programming and is intended for readers unfamiliar with the subject matter.
The “end” of Moore’s law
Until the mid-2000s, the computing capability of microprocessors enjoyed an impressive growth that was explained by the observation that the number of transistors on a processor chip doubled roughly every 18 months (Moore’s law1) while the power consumption remained constant (Dennard scaling2). This meant that it was possible to produce faster processors, i.e., processors with higher clock speeds, by increasing the transistor count without observing a corresponding rise in the energy required to operate them. Around 2003-2004, CPU performance started to flatten3. As chips became denser with tinier transistors running at higher clock speeds, heat dissipation turned into an issue, and energy usage began to grow dramatically. Seeing that these obstacles made it difficult to achieve ever higher clock speeds, the focus shifted toward designing multicore chips capable of processing tasks in parallel. Thus, the performance gain, as measured by the number of instructions per clock cycle, was achieved by raising the processor core count to enable parallelism instead of enhancing the computing power of the individual core.
Why GPUs?
In recent years, the need to deliver exascale computing capability and the emergence of data-intensive applications such as artificial intelligence (AI) in the form of machine learning prompted the adoption of hardware accelerators4 to further increase computing performance beyond what multicore technology can deliver. An accelerator is any piece of specialized hardware capable of performing certain functions more efficiently than general-purpose processors, and it is used to complement the CPU with the goal of increasing throughput. Of particular interest for scientific computing are Graphic Processor Unit (GPU) accelerators. While CPUs excel at performing a wide variety of tasks efficiently, they are capable of executing only a few threads in parallel. In contrast, GPUs are specialized in data processing tasks and designed with thousands of processing cores to enable massive parallelism. Thus, they are particularly suited for highly parallel and repetitive computing tasks often found in scientific applications. Currently, six of the ten fastest supercomputers in the world are GPU-accelerated systems5, and more are going to be deployed in the near future based on accelerators from Intel, AMD, and Nvidia.
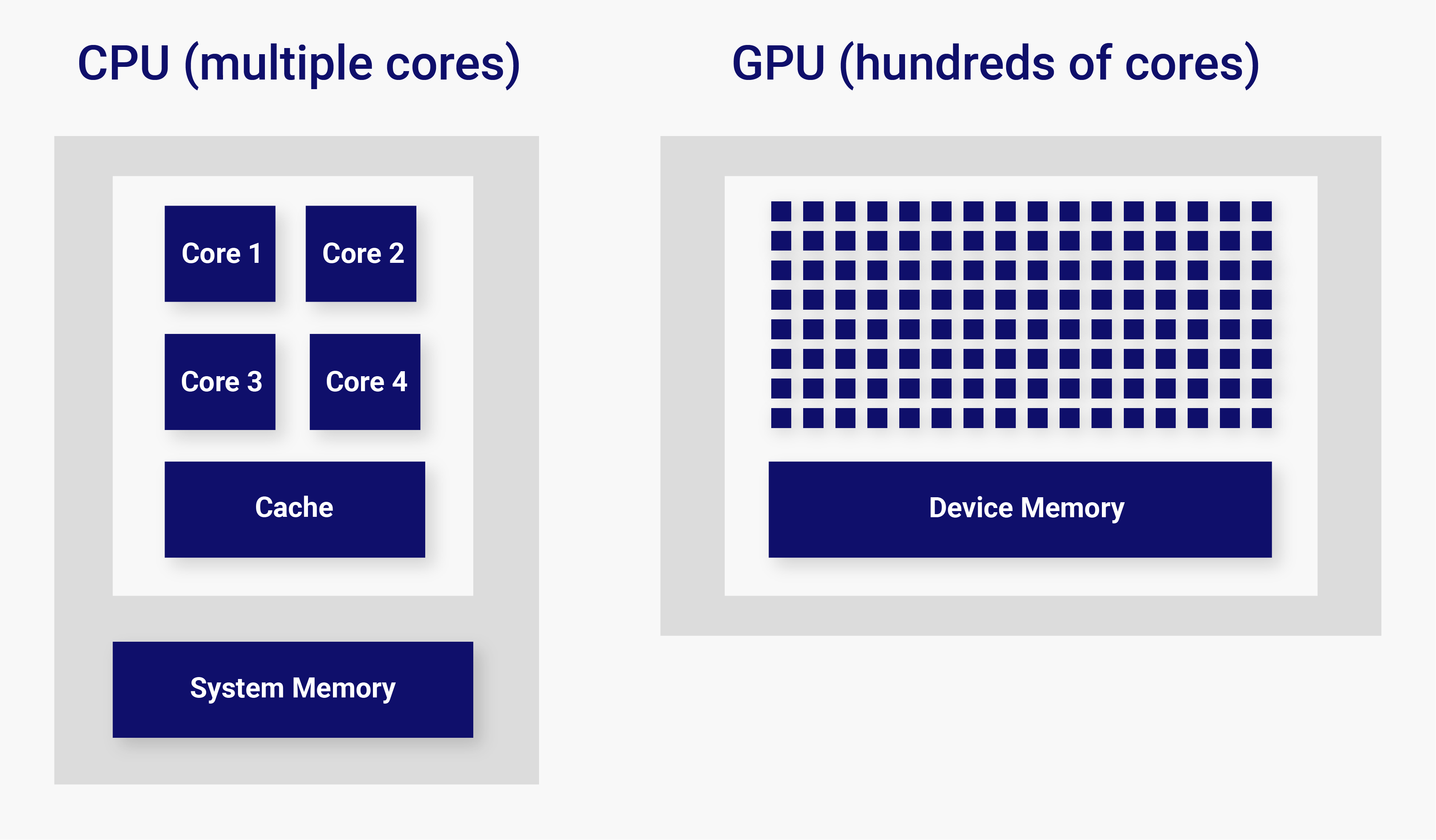
Host vs device
On GPU-enabled systems, a heterogeneous programming model leveraging both CPU and GPU is typically used. In this model, the CPU and its memory are referred to as the host, and the GPU and its memory as the device. Typically, the host can run only a limited number of concurrent threads, whereas the device can handle thousands of them. As a result, the device is best suited for calculations that are parallel in nature, where the same operation can be performed on a large number of data elements at the same time. It follows that code run on the host commonly executes general-purpose tasks, including memory management for both the host and the device, and offloads computationally intensive operations to the device by launching specialized functions known as kernels. GPU kernel launches incur a considerable overhead compared to CPU function calls; therefore, their use is appropriate when performing heavy computations. For this reason, it is often best for performance to combine two or more small computational kernels into a single GPU kernel (kernel fusion) when possible.
Data transfers between host and device
Because host and device have their own separate memory, transfers of data between the two are often necessary. However, such transfers are relatively slow compared to the speed at which GPUs can perform calculations. To this end, it is beneficial to structure the algorithm in such a way that it minimizes transferring data between the host and the device as much as possible. When data exchange is unavoidable, few large transfers should be preferred over many small ones in order to limit the cumulative effect of the overhead associated with each transfer, even at the cost of packing/unpacking non-contiguous chunks of data into send/receive buffers. Additionally, the impact of data communications should be further mitigated by overlapping kernel execution with data transfers whenever possible.
Another consideration is whether to explicitly manage host to device transfers or to rely on abstractions such as CUDA's Unified Virtual Memory (UVM) or Intel's Unified Shared Memory (USM). These capabilities present host and device memory together using a single address space, managing data motion under the hood. This allows developers to think of host and device memory spaces as logically one. The downsides are that application developers have less control over data motion, and that the page-fault detection mechanism used to develop these features introduces some overhead. However, these trade-offs may be worth the ease of development that comes with not having to explicitly manage data transfers.
Total memory footprint
Data copied to the device should be kept there for as long as possible by allowing multiple kernels to perform successive calculations on the data before copying it back to the host. Even if some of these calculations do not parallelize well and could be run faster on the host, it may still be more efficient to execute them on the device if this means eliding intermediate copies. Ideally, all the data needed by an application would be transferred once and kept on device memory at all times, but this may not always be possible due to device memory size limitations. Thus, reducing the total memory footprint of an application becomes a very important optimization target.
Similar considerations apply to supercomputing clusters such as the Summit6 machine at Oak Ridge National Laboratory - at the time of this writing, second on the top 500 list of the world’s fastest supercomputers. While Summit has over 10 Petabytes of total system memory, it has only a bit over 400 Terabytes of device memory - considerably less than the total system memory available on previous-generation supercomputers like NERSC’s Cori7. Thus, if you are running in a mode where your entire problem fits on the device at all times - desirable given the aforementioned expense of host-device transfers - it is difficult to run as large a problem on Summit as you could on Cori. This circumstance further highlights the importance of reducing the overall memory footprint of an application.
Memory allocation on the device
Leveraging device memory to store temporary data structures is advantageous to reduce host/device data transfers. However, memory allocation is much slower on the device than on the host and should be used with care. In particular, frequent allocations of small chunks of memory negatively impact performance and should be avoided by using memory “arenas” instead. A memory arena is a large continuous share of memory that is created/destroyed all at once, oftentimes at the beginning/end of program execution. Arenas are typically managed by specialized classes that handle the allocation/deallocation process and dispatch chunks of it to other objects for use as storage as requested by the program. When these objects are destroyed, the arena marks the associated chunk of memory as free without any deallocation involved. The advantage is that device memory is reused, and calls to system allocation functions are minimized. In this way, dynamic data structures can be used without incurring prohibitive memory allocation costs.
Consider the roofline
As with CPU functions, GPU kernel performance can be either compute bound, meaning limited by the number of floating point operations per second the accelerator hardware can perform, or memory bound, meaning limited by the rate at which can be streamed to the multiprocessors either from main memory or from various levels of the cache hierarchy. The roofline model8 is a method for visually reasoning about the way these factors limit the performance of computational kernels. By virtue of the GPUs' impressive floating-point performance, it is common for GPU kernels in scientific codes to be memory bound. Consequently, it is often faster to recompute intermediate results than save them for other kernels to use. This approach may help reduce the number of allocations on device memory and the total memory footprint of the application.
Note that the roofline model does not factor in latency, a measure of how long a processor takes after starting an instruction for the result to be ready to be used by another instruction. CPUs use sophisticated branch prediction and speculative fetching to minimize latency, whereas GPUs use massive parallelism to maximize throughput. As a result, the roofline model tends to be a better guide for GPU codes than CPU codes; however, it can still be a useful way to think about some GPU kernels.
Conclusion
GPU computing offers remarkable potential for speeding up many scientific workloads. Even if code modifications are usually necessary to evade the performance bottlenecks outlined above, exceptional speed ups are possible.
For further reading:
-
CUDA Toolkit Documentation
-
GPU offloading with OpenMP
-
ROCm documentation
-
DPC++ Reference documentation
-
Performance Portability and the Exascale Computing Project
Author bios
Michele Rosso is a Project Scientist in the Center for Computational Sciences and Engineering at Lawrence Berkeley National Laboratory. His research focuses on the development and implementation of adaptive mesh multi-physics algorithms for many-cores and GPU architectures. He contributes to several computational fluid dynamics software projects, including the MFIX-Exa multi-phase flow simulation tool and the adaptive mesh Navier-Stokes solver code IAMR.
Andrew Myers is a Computer Systems Engineer in the Center for Computational Sciences and Engineering at Lawrence Berkeley National Laboratory. His work focuses on scalable particle methods for emerging architectures in the context of adaptive mesh refinement. He is a core contributor to several GPU-ready open-source scientific software projects, including the AMReX adaptive mesh refinement framework and the electromagnetic Particle-in-Cell code WarpX.

